Undocumented Computer Code Used by Prof. Neil Ferguson to Advise UK to Commit Economic Suicide
 international |
economics and finance |
feature
international |
economics and finance |
feature  Friday May 22, 2020 00:01
Friday May 22, 2020 00:01 by 1 of indy
by 1 of indy
Undocumented Code is notoriously error prone and buggy.
Prof Neil Ferguson who was the chief advisor to the UK government in the lead up to the Covid lockdown and was instrumental in bringing it about based his advice the output of his own undocumented computer code he wrote 13 years ago. In the initial stages of the crisis his "model" predicted 500,000 deaths in the UK from Covid. Then a short time later, he revised his figures sharply downward and said his model now predicted to 20,000 deaths. This incidentally is the same number of deaths from flu in the UK in a typical year. So it appears to be the case that the UK has committed economic suicide based on software that no-one else could inspect in advance nor was there any independent verification. To make decisions based on this type of methodology is nothing short of criminal. And we haven't even got to the assumptions used which obviously are on equally shaky ground given one day the model was predicting 500,000 dead and then when obviously some level of correction was done, it was then only 20,000.
Related Links: COVID 19 Is A Statistical Nonsense | The Vaunted R Number the UK Is Destroying Itself Over Is Shamanic Mumbo Jumbo Not only is the data going in weak and uncertain, but even the core assumptions of the model are educated guesses subject to bias | Covid-19: Neil Ferguson, the Liberal Lyssenko | Sweden Has Covid-19 Beat, Leaving Everyone Who Locked Down With Egg on Their Face
Computer models such as Ferguson's one for the spread of disease are really just software wrapped around a few mathematical equations. If the parameters of the equation are wrong then the output will be wrong. Quite often parameters are based on initial guesses and would then ideally be checked whether the values used correspond to reality in real life.
Separately computer code is quite often error prone and simple logical errors can be often very hard to find in the thousands of lines of computer code. All software in industry will typical undergo multiple rows of hundreds of tests to ensure a piece of software is doing what it is supposed to do and even though most companies relying on software they have bought will have maintenance contracts to fix problems as they are found. The Linux software which runs nearly every web-server and back-end industrial scale piece of software is free software that can and is available for the public to see and tens of thousands of software geeks are involved. The same is true for many other common programs used like the Firefox browser.
The internet runs on software and there is an awful out there and many people make it publically available. This allows others to inspect, find and fix problems and is an very effective way of doing things. This is widespread and standard practice. In the software industry and community it is good practice to document the code and in cases where there are not strict commercial considerations, to make it available for other to see.
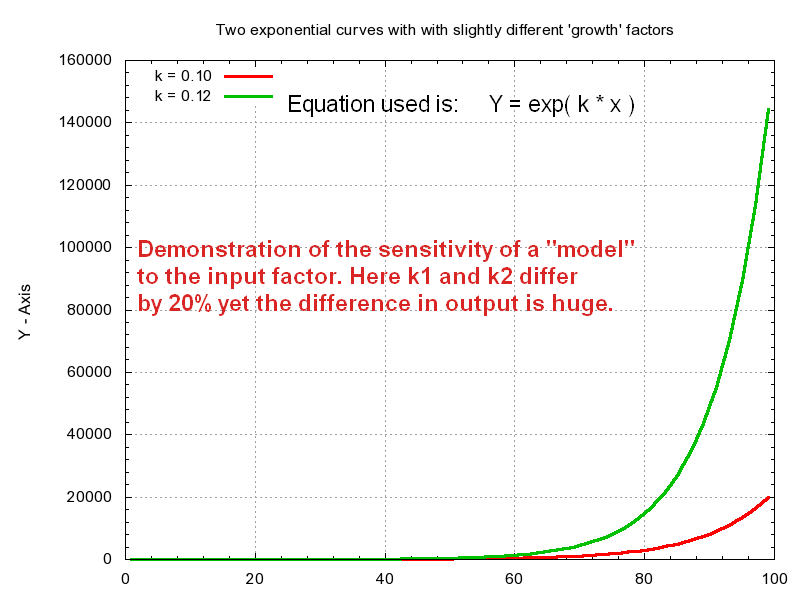
Model Assumptions Can Make Huge Difference to the Model Output
Regarding the models themselves the public needs to make the effort to understand some basic things about these and that is to be very cautious and skeptical in general. The image here of the two curves is a plot of the output of a very simple exponential mathematical equation except the difference between the two of them is a k factor. All sorts of models used exponential equations in them and ones that track "growth" and "death" dynamics would also have their own equivalent of the k factor. They may even have several. These factors represent things like the infection rate or the mortality rate. In this plot we can see there is a huge difference in the output by just a small 20% change in the k factor. When people run models they often take an "educated" guess at the value of these factors because they don't know what the true value is. It is imperative that the true real world value corresponding to it is measured and to high accuracy.
In many ways this is the question that should be asked of all the models because if the assumptions are wrong and they are often are not precise enough then you will get unrealistic outputs and it is simply extremely foolish to make costly decisions based on them. However, assuming for a moment the covid thing is all a big mistake, what we have here is a bunch of academics like Ferguson and his peers who would be in key positions in the World Health Organisation (WHO) that suddenly find themselves on the world stage making decision affecting hundreds to billions of people. This leads to question whether these people were just pawns in a bigger game since once the lockdown was in place the whole thing had a momentum of it's own and there are still many willing enforcers. It is unlikely that this can be rolled back without a huge loss of face by many, reputations tarnished and that of the media too because it has been completely uncritical.
The Undocumented Software and Response by Computer Software pundits
When Neil Ferguson announced his software it clearly came as a shock to people who work professionally in software. His response was to give it to Microsoft to put a fancy web interface on it. This is the exact same as putting lipstick on a pig!. The proper thing to do would be release it to the public immediately. By giving it to Microsoft, they no doubt will be tasked with correcting all the programming errors and putting bells and whistles on it. What the public ought to demand and has a right to know is the actual software that ran when Neil Ferguson used it's output to make Covid death projections and to panic the UK government into shutting down the economy.
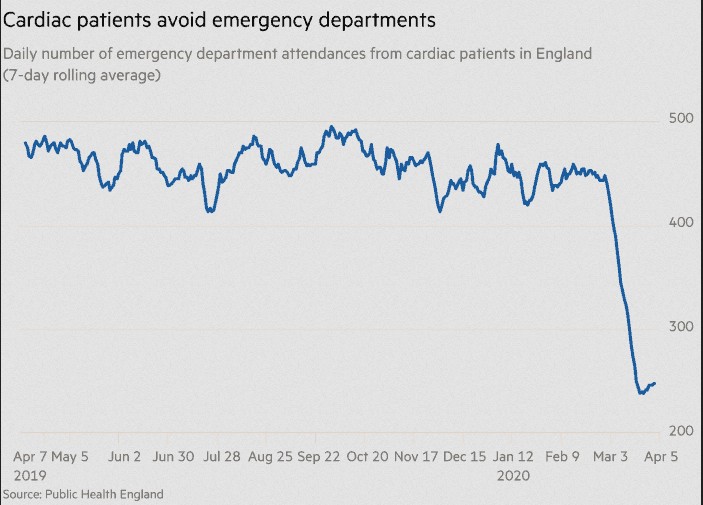
There is a lot at stake here from huge financial losses, millions out of work, tens of thousands of businesses going bust and a host of other equally large knock effects. On the social side, it is now reported that up to 600 people in London alone are dying of heart attacks each week, because they are afraid to go to hospitals when normally they would go. These figures are derived from the massive drop in attendance at emergency departments from cardiac patients in hospital. Given the London population of approximately 10 million or one sixth of the country, this means about 3,600 needless deaths per week just from cardiac problems alone in the UK.
The response to Ferguson has been illuminating and revealing. Who would have thought this is what was behind the "expert" scientific models. Unfortunately the public tends to equate software with science. It is not the same thing and the science is only as good as the real world data. Yet in some ways we have to congratulate him for his honesty and openness, although . For instance here are some of the messages on Twitter but first bear in mind the following. The code was also given to github where some people will be have access to it. But what they see on github will be the modified code -i.e. refactored. It is very important to note this is NOT the original. Due to the large gaff, there is no doubt there will be every attempt to fix it up and then for supporters to chime in at how wonderful it is.
Some of these response have been captured in the screenshots below as it is likely that when knowledge of this grows that it will disappear.Some of the Twitter Responses
Roko Mijic @RokoMijicUK · Mar 22
(6 months later)
"A bug on line 3471 caused the model to overestimate deaths by a factor of 100. The lockdown was unnecessary
But by being in C we got a 50% performance boost!"
Roko Mijic @RokoMijicUK · Mar 23
Our society very clearly misallocates resources. A serious bug in this code would cost £ trillions yet in the past 13 years there wasn't like a whole team of the absolute best engineers getting it up to a tip-top state. I'm not blaming the researchers. It's just a crazy world.
[Update: Indy Editors note. Even if the code is perfect, the assumptions have to be correct. See image above]
CFD Direct OpenFOAM @CFDdirect Mar 23
Replying to @neil_ferguson
1/19 It is disappointing that critical decisions relating to the #COVID?19 crisis in public health and the economy rely on scientific software containing "thousands of lines of undocumented C" source code, which has never been publicly accessible. THREAD
Julia Walsh @Julia14235 · Mar 22
Replying to @tom_collings_uk and @neil_ferguson
As a systems auditor my stomach did a flip when I read thousands of lines of undocumented C.
Arguably Wrong @arguablywrong Mar 23
Or --- get this --- he could have shared the code 14 years ago when he published the first paper using it.
See new Tweets Conversation 1 more reply
Stefan Karpinski @StefanKarpinski · Mar 23
Why havent you just immediately released the code and allowed tbe global community to dissect it and work on it? Now is not the time to be embarrassed about some code. Youre missing the power of open source to accomplish feats, especially when people are highly motivated
18 more replies
@drklausner · Mar 23
Replying to @neil_ferguson
We dont need your code Neal we need to understand your assumptions and how are you change those assumptions overtime
Jim Rafferty @DrJimRafferty · Mar 23
We do need the code, because otherwise how will we know if the stated assumptions are implemented correctly?

